.avif)
AI Scriper -- How AI-Powered Scrapers Are Redefining Red Teaming

Introduction
As organizations increasingly rely on web scraping for competitive intelligence, market research, and data aggregation, the battle between scrapers and anti-scraping defenses has intensified. Traditional scraping methods, while effective in their time, are showing their limitations against modern anti-bot technologies. At HydroX AI, our red teaming research has uncovered a fundamental shift: AI-powered scrapers are not just faster—they're fundamentally more resilient and adaptive than their traditional counterparts.
How AI Scrapers Are Redefining Web Scraping
AI-powered scrapers leverage Large Language Models (LLMs) to fundamentally change how web scraping works. Instead of relying on rigid parsing rules, they use semantic understanding and adaptive extraction to overcome the limitations of traditional scrapers.
Key Advantages Over Traditional Scrapers
Core Capabilities
Semantic Understanding:
- Identifies content by meaning, not structure
- Handles DOM changes automatically without developer intervention
- Processes JavaScript-rendered pages and complex layouts
- Adapts to different page structures, languages, and layouts
Zero-Code Adaptation:
- When a website changes its DOM structure, AI scrapers adapt within minutes
- No manual code fixes or redeployment required
- Maintains continuous operation during website updates
Advanced Anti-Scraping Evasion:
- Behavioral mimicry: Generates human-like browsing patterns
- Dynamic request generation: Adapts headers, timing, and patterns based on context
- Intelligent retry logic: Understands error messages and adapts strategies
- Context-aware navigation: Handles complex multi-step workflows
Two AI Scraper Architectures for Red Teaming
AI-powered scrapers typically follow one of two architectural approaches, each with distinct advantages for red teaming and anti-scraping evasion:
Architecture 1: Traditional Scraping + LLM Understanding
This hybrid approach combines traditional web scraping techniques with LLM-powered content understanding.
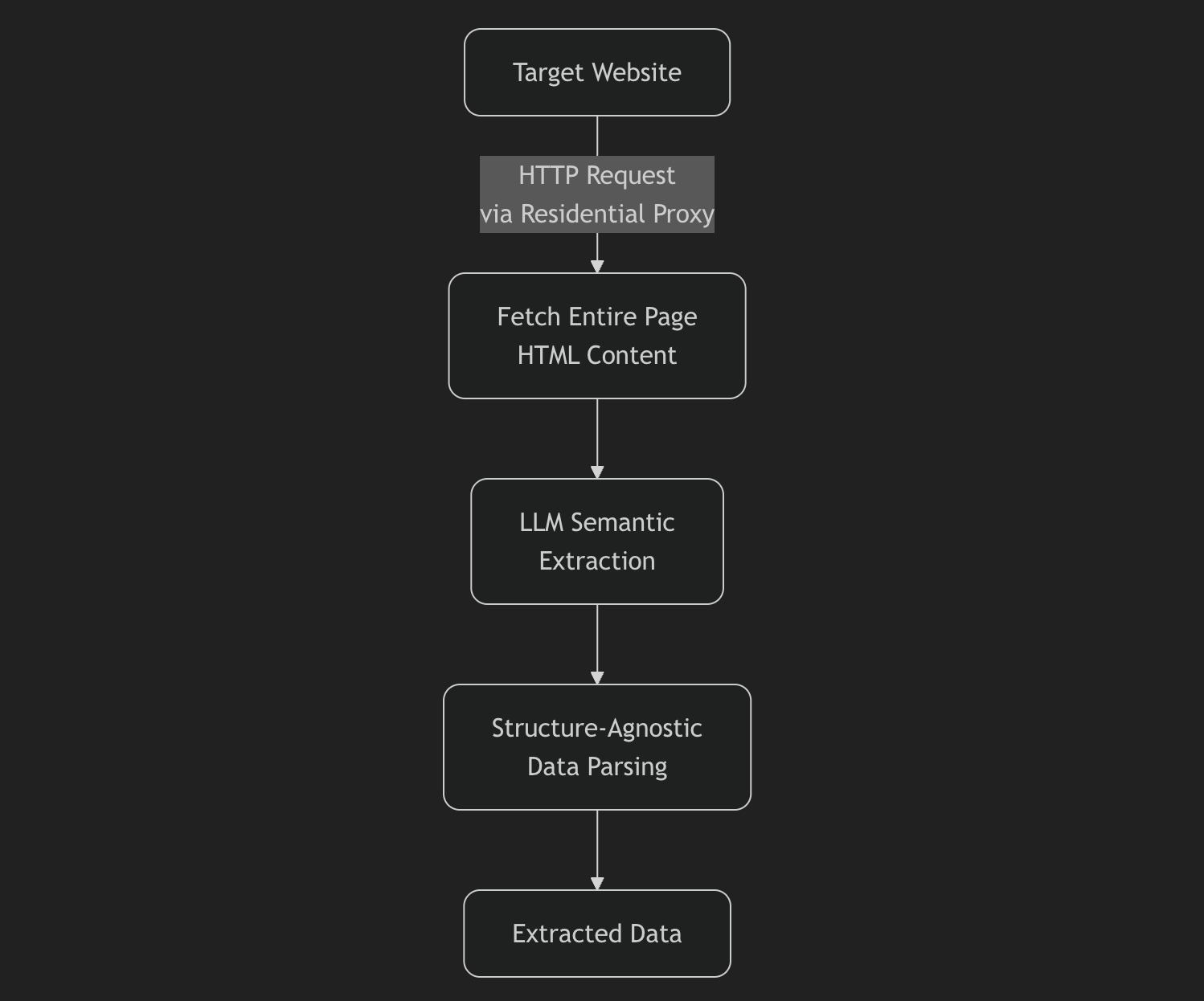
Workflow:
- Fetch entire page: Use HTTP requests (via residential proxies) to download complete HTML content
- LLM semantic extraction: Pass the full page content to an LLM for intelligent data extraction
- Structure-agnostic parsing: LLM identifies and extracts target data based on semantic meaning, not DOM structure
Red Teaming Advantages:
- Comprehensive content access: Captures entire page context, including dynamically rendered content
- Robust extraction: LLM can handle complex layouts, nested structures, and multi-format data
- Error resilience: Can extract partial data even when page structure changes
- Cost-effective: Single LLM call per page, efficient for bulk operations
- Breaks anti-scraping mechanisms: Semantic understanding bypasses DOM-based detection
Use Cases:
- E-commerce product information extraction
- News article and content scraping
- Real estate listing aggregation
- Job posting data collection
Architecture 2: AI Agent-Driven Request Generation
This advanced approach uses AI agents to autonomously navigate and interact with websites.

Workflow:
- Agent planning: LLM analyzes target website and generates navigation strategy
- Intelligent request generation: Agent creates contextually appropriate HTTP requests (via residential proxies)
- Dynamic interaction: Agent adapts requests based on responses, handling forms, pagination, and dynamic content
- Semantic data extraction: Agent extracts data while navigating, understanding page context in real-time
Red Teaming Advantages:
- Autonomous navigation: Can handle complex multi-step workflows without pre-programming
- Adaptive behavior: Adjusts strategy based on website responses and anti-bot measures
- Human-like interaction: Mimics real user behavior, reducing detection risk
- Dynamic content handling: Can interact with JavaScript-heavy sites, forms, and APIs
- Breaks advanced anti-scraping: Behavioral mimicry evades fingerprinting and pattern detection
Use Cases:
- Multi-step form submissions
- Complex search and filter workflows
- API endpoint discovery and interaction
- Dynamic content that requires user interaction
Why Red Teaming Matters for AI Scraping
Red teaming is essential for understanding and defending against AI-powered scraping threats. As AI scrapers become increasingly sophisticated, organizations must adopt proactive security measures:
1. Proactive Threat Assessment
- Identify vulnerabilities before attackers exploit them: Red teaming reveals how AI scrapers can bypass existing anti-scraping defenses
- Real-world validation: Testing against actual AI scraping techniques provides accurate risk assessment
- Stay ahead of threats: Understanding emerging AI scraping capabilities helps organizations prepare defenses before attacks occur
2. Defense Validation
- Test anti-scraping measures: Red teaming validates whether current defenses can withstand AI-powered attacks
- Gap identification: Reveals weaknesses in existing security measures that need strengthening
- Continuous improvement: Ongoing red teaming ensures defenses evolve with advancing threats
3. Risk Mitigation
- Data exposure analysis: Understand what data could be extracted by AI scrapers from public-facing systems
- Compliance validation: Ensure GDPR, CCPA, and other privacy regulations are met against AI scraping threats
- Reputational protection: Prevent unauthorized data extraction that could damage brand reputation
4. Strategic Advantage
- Informed security decisions: Data-driven insights from red teaming guide security strategy development
- Competitive edge: Organizations with robust red teaming capabilities have better protection than competitors
- Resource optimization: Focus security investments on areas most vulnerable to AI scraping attacks
At HydroX AI, our red teaming capabilities combine advanced AI research with production-grade infrastructure to provide organizations with comprehensive threat assessment and defense validation services.
The Critical Role of Residential Proxies
Regardless of which AI scraper architecture is employed, residential proxy infrastructure is fundamental to successful anti-scraping evasion. In red teaming scenarios, residential proxies are increasingly becoming the most critical component.
Why Residential IPs Matter for Anti-Scraping Evasion
1. IP Reputation and Trust
- Datacenter IPs: Easily identified and blocked by anti-bot systems
- Residential IPs: Associated with real ISPs and devices, appearing as legitimate user traffic
- Trust score: Residential IPs have higher trust scores in anti-bot detection systems
2. Behavioral Authenticity
- Geographic diversity: Residential IPs span real locations, matching expected user distribution
- ISP variety: Multiple Internet Service Providers create realistic traffic patterns
- Device fingerprints: Residential IPs correlate with diverse device types and browser configurations
3. Detection Evasion
- Rate limiting: Residential IPs can handle higher request volumes without triggering alarms
- Pattern masking: Distributed residential IPs obscure scraping patterns
- CAPTCHA reduction: Legitimate-looking IPs reduce CAPTCHA challenges
- Session continuity: Maintains realistic session patterns across multi-step workflows
Impact on AI Scraper Architectures
For Architecture 1 (Traditional Scraping + LLM):
- High-volume page fetching: Residential IPs enable bulk HTML downloads without triggering rate limits
- IP reputation: Legitimate residential IPs reduce blocking risk during page retrieval
- Geographic targeting: Route requests through appropriate regions for target websites
For Architecture 2 (AI Agent-Driven):
- Human-like navigation: Residential IPs provide authentic IP addresses for agent interactions
- Behavioral mimicry: Real ISP associations enable realistic browsing patterns
- Multi-step workflows: Residential IPs maintain session continuity across complex interactions
HydroX Advantage: 60M+ Residential IP Network with Ground Truth Validation
At HydroX, our red teaming infrastructure leverages over 60 million residential IP addresses to ensure maximum success rates. Our extensive IP network is built through comprehensive monitoring and integration of major proxy providers across the industry, ensuring we have access to the highest-quality residential IPs available.
Network Composition:
- 60M+ residential IPs: Aggregated from leading residential proxy providers worldwide
- Comprehensive provider monitoring: Ongoing evaluation of major proxy providers' performance and reliability
- Quality aggregation: Selection of highest-quality IPs from monitored providers
- Geographic coverage: IPs from 200+ countries and regions through diverse provider networks
- ISP diversity: Multiple providers per region for realistic distribution
Ground Truth Validation:
- Real-world testing: Validated against actual production websites and anti-bot systems
- Accurate metrics: True success rates, not theoretical estimates
- Comprehensive coverage: Testing across diverse website types and anti-bot systems
- Continuous validation: Ongoing testing to track effectiveness over time
Dynamic IP Library Management:
- Multi-provider integration: Seamlessly routes requests across IPs from multiple monitored proxy providers
- Continuous rotation: Automatic IP rotation across provider networks to avoid detection
- Provider performance tracking: Real-time evaluation of each proxy provider's success rates and reliability
- Quality assurance: Real-time monitoring of IP health and success rates across all integrated providers
- Geographic targeting: Ability to route requests through specific regions using the best available provider
- Performance optimization: Intelligent routing based on latency, success metrics, and provider performance
- Failover capabilities: Automatic switching between providers when performance degrades
Without robust residential proxy infrastructure, even the most sophisticated AI scrapers will face:
- Rapid IP blocking and blacklisting
- Increased CAPTCHA challenges
- Reduced success rates
- Higher operational costs
Conclusion
The evolution from traditional to AI-powered scraping represents a fundamental shift in the threat landscape. AI scrapers, whether using traditional scraping + LLM understanding or AI agent-driven approaches, can break through numerous anti-scraping mechanisms through semantic understanding, adaptive behavior, and intelligent navigation.
However, residential proxy infrastructure remains the critical foundation for successful anti-scraping evasion. At HydroX AI, our combination of advanced AI research, 60M+ residential IP network (monitored from major proxy providers), and ground truth testing capabilities provides organizations with the insights they need to understand and defend against these advanced threats.




